







 BIG DATA
BIG DATA
BIG DATA
BIG DATA
BIG DATA
Given that data platforms have an estimated total addressable market in the tens of billions of dollars, it comes as no surprise that every vendor offering data-related solutions is striving to secure its share of this highly lucrative market.
But the real question is: How do these different approaches compare? Today, on a new segment called Analyst Angle (full video below), we break it down, extracting the signal from the noise, to explore what truly defines a data platform.
Before delving into the details, let’s establish what we mean by a data platform. Our Angle is that a data platform is more than a storage solution. It offers comprehensive functionality, including the ability to access data programmatically through SQL queries and RESTful application programming interfaces, built-in virtualization tools, and the capability to extract, transform and load data to and from various sources, such as data warehouses, data lakes, and object storage.
Additionally, it should support data access protocols such as ODBC or JDBC, enabling efficient data utilization. In essence, a data platform is a holistic solution that not only stores data but also provides APIs for data ingestion, processing methods, data governance, scalability and performance to meet cloud-scale demands, regardless of location. Such platforms can be delivered as customizable build-your-own solutions or as convenient as-a-service offerings.
To gauge both the maturity and competitive landscape of the data platform market, I collaborated with fellow analyst Dave Vellante and analyzed data provided by our partner Enterprise Technology Research. Our research aimed to answer questions such as the market’s maturity, the presence of a dominant player, and the varied approaches adopted by vendors.
The thesis we explored suggested that though some commercial data platform vendors, including Snowflake and Databricks, hold significant market share, there is still substantial room for growth. Our recent Breaking Analysis revealed this market’s potential, indicating that no dominant player has emerged just yet. Today, we take a closer look, examining the extent of the market’s opportunities and gaining a deeper understanding of its dynamics.
To gain insights into the landscape, we leveraged ETR’s data and examined the prevalence of different storage vendors, including Dell Technologies Inc.’s EMC, NetApp Inc., VAST Data Inc., Pure Storage Inc., Hewlett Packard Enterprise Co., IBM Corp. and others, across various accounts. This formed the baseline, providing a reference point we could build upon.
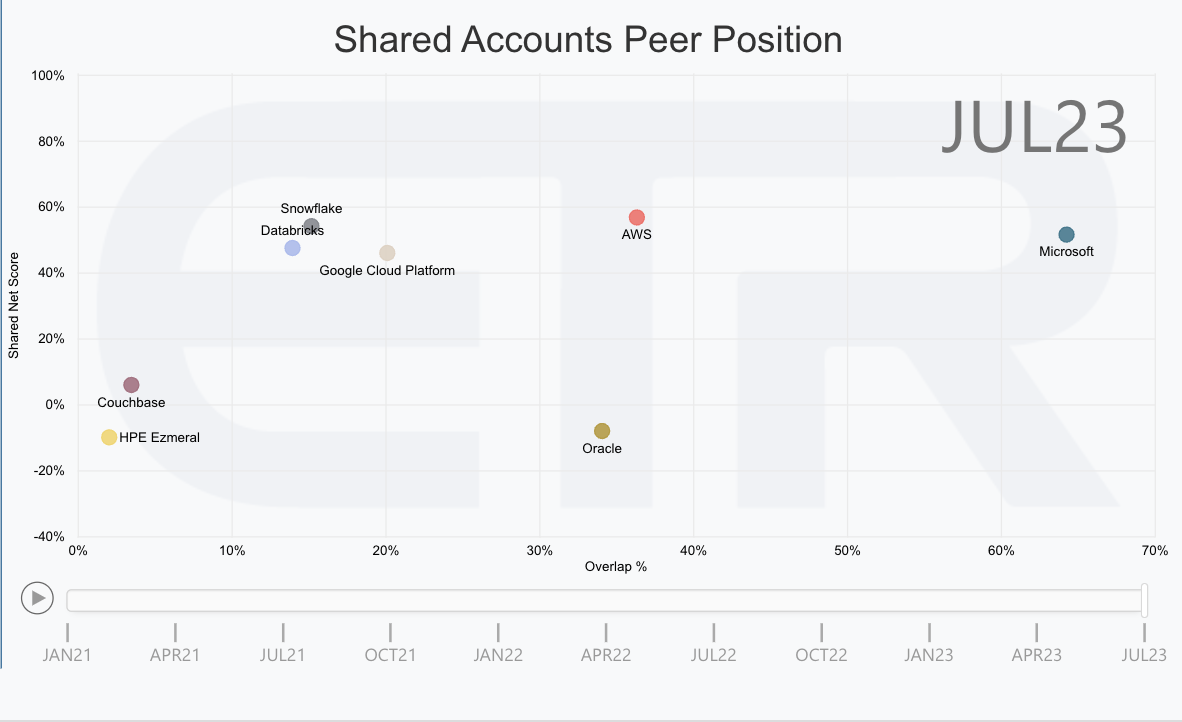
Additionally, we scrutinized the occurrence of popular data platforms such as Databricks, Snowflake, Amazon Web Services, Google, Microsoft, Oracle, HPE’s Ezmeral and Couchbase within these accounts. We observed a considerable sample size of more than 480 accounts, ensuring the reliability of our findings. By analyzing the momentum and prevalence of these platforms, we gained valuable insights into their respective market shares.
Our analysis revealed intriguing trends. Notably, Microsoft emerged as the leader in terms of awareness and mentions within these accounts, around the 70% mark. AWS and Google followed closely, with AWS positioned in the middle and Google making its presence felt around the 30% mark. What fascinated us was the overall momentum of these major players. Microsoft, AWS, Google, Snowflake and Databricks all exceeded the 40% threshold, indicating their growing market shares within these accounts.
In comparison, Couchbase secured over 5% market share, while HPE’s Ezmeral experienced a negative 10%, meaning its influence was shrinking. These findings shed light on where market attention lies and emphasize the room for growth. Despite the rapid expansion of Snowflake and Databricks, they have yet to become pervasive across accounts, suggesting a significant untapped total addressable market remains. This is an opportunity for all of the vendors in this market.
These findings lead us to explore the characteristics of different data platform types. It is important to note that these categories are not mutually exclusive, as many companies may use multiple platforms that may overlap in functionality. Our approach to categorization employs a simplified SWO analysis, focusing on the strengths, weaknesses and opportunities presented by each platform type. By taking this approach, we aim to gain insights into the use cases and caveats associated with various data platform approaches.
In the upcoming sections, we will navigate through the intricacies of each platform type, exploring their unique qualities and uncovering the opportunities they offer in building data products.
These platforms provide several strengths that make them attractive options. First, they offer multiple ways to access data programmatically, including data lakes, data warehouses, SQL, Python and RESTful APIs. This flexibility in data access is crucial for users to effectively use the data and engineer their applications.
Additionally, these platforms provide normalized and programmatic methods for ingesting data, ensuring that users can efficiently bring their data into the platform and build pipelines on top of it. Moreover, they offer catalog and data mapping features that promote effective governance, enabling users to understand the lineage of their data and ensuring compliance with regulations.
These platforms also come with built-in storage options, ranging from object to file storage, allowing users to choose the architecture that suits their needs and cost preferences. Furthermore, these platforms excel in scalability and performance, making them suitable for cloud-scale deployments. They often leverage open-source components for their scaling capabilities, providing users with a reliable and efficient infrastructure.
However, there are weaknesses that users should consider when evaluating these platforms. One challenge lies in understanding and comparing the cost of the services, especially when it comes to bring-your-own-storage models. It can be complicated to determine the costs when comparing on-premise solutions to cloud-based services.
Additionally, the availability of options to run these platforms in co-location facilities or on-premise data centers may be limited, posing constraints for users who require specific deployment environments. Another aspect to consider is the variability in cost-effectiveness, as different platforms may offer different pricing structures and models.
On the other hand, there are opportunities for improvement and expansion in these platforms. Deploying them in colocation facilities, sovereign clouds or on-premises settings can be viable options if the underlying platform is designed correctly. Although there may be cost calculations and market considerations involved, vendors are increasingly exploring partnerships and options to make their platforms available in different environments. The desire to move beyond a few dominant cloud providers creates opportunities for vendors to offer their services in colocation or sovereign cloud settings.
Moving on to hyperscale cloud providers such as AWS, Microsoft Azure, Google Cloud and Oracle Cloud, these companies offer a wide range of services that rival the capabilities of independent as-a-service data platform vendors. These providers often partner with independent vendors and offer their data platforms as first-party services. For example, Databricks runs on Azure, provided as a first-party Microsoft service.
The strengths of hyperscaler clouds include a broad array of services covering data warehousing, data lakes, and data mesh. They offer various options to address different use cases and frequently incorporate built-in artificial intelligence and machine learning capabilities.
Moreover, they often have low initial pricing and enterprise contracts in place, making it easier for experimentation and driving momentum for adoption. Their built-in storage platforms, cloud-scale infrastructure and performance capabilities are additional advantages. Hyperscaler clouds also provide a choice of services that can be used to solve specific problems, enabling users to leverage a diverse set of tools.
However, one weakness of hyperscaler clouds is the potential overlap between services, requiring users to integrate different components or smaller services to achieve their desired data platform. Another limitation is the lock-in to a specific cloud provider, which can make migration and data movement complex and costly. Additionally, the availability of services in certain regions or countries may pose challenges, particularly due to regulatory requirements.
Despite these weaknesses, there are opportunities for hyperscaler clouds, often in collaboration with independent data platform vendors, generating revenue from compute, network, and storage usage. Also, hyperscale clouds understand that customers are looking for solutions, not services, and can do a better, if not slower, job to build to those customer requirements.
In addition to commercial data platforms and hyperscaler clouds, traditional data storage platform vendors play a significant role in the data platform space. These vendors, such as HPE, Pure Storage, VAST Data, Dell and Hitachi Vantara, have a strong foundation in building economical storage offerings, including opex or capex acquisition methods.
Strengths for storage based data platforms start with strong support of various types of storage, including object, file and block storage, within a single scalable platform. Additionally, they frequently package storage offerings with compute platforms or cloud operating environments, enabling quick setup and deployment. Their partnerships with colocation facilities and managed service providers enhance regional support and provide a breadth of options for customers.
However, one weakness of these platforms is the lack of pre-installed data warehouse, data lake or data mesh environments, requiring customers to integrate additional products to overlay on top of their storage foundation. Furthermore, most of these platforms do not run natively in hyperscale clouds, limiting the flexibility for users who prefer cloud-native solutions.
The opportunities for storage platform vendors and data platform vendors lie in integrating data platforms as-a-service into their storage offerings. This integration can address the cost and value challenges faced by data engineers and chief information officers.
Additionally, regulatory requirements may push data platforms toward colocation, sovereign clouds and regional cloud providers, providing further opportunities for these vendors. Storage platform vendors can leverage their networking solutions to offer cost advantages by eliminating egress or ingress fees associated with data movement. Furthermore, by focusing on customer requirements and improving customer experience, storage platform vendors can compete with commercial data platforms and provide compelling solutions.
Finally, open-source data platforms, predominantly available through supporting commercial entities, offer innovation and flexibility. Examples include the underpinnings of many of the commercial products as Lego building blocks, such as Apache Spark, Delta Lake, Presto, Trino and much much more.
Some of the strengths are the various ways to access data programmatically and can be customized based on organizational requirements. However, building an open-source data platform requires significant system integration work on the user’s end and potentially skill sets that they will need to hire.
A weakness is that governance features, such as cataloging and data mapping, may not be built-in, leading to potential data platform silos or inadequate data access controls. Another weakness is that organizations must consider whether open source solutions align with their core business or are merely science projects, as the cost and complexity can escalate quickly. Free software is not free.
Nevertheless, the opportunity is that open-source platforms continue to drive innovation, and active participation in the open-source community can provide valuable insights and inspiration for building robust data platforms. So being involved and understanding the open-source platforms, or at least tracking them, is super-important. We do a lot with open source and we are very bullish on where it’s going.
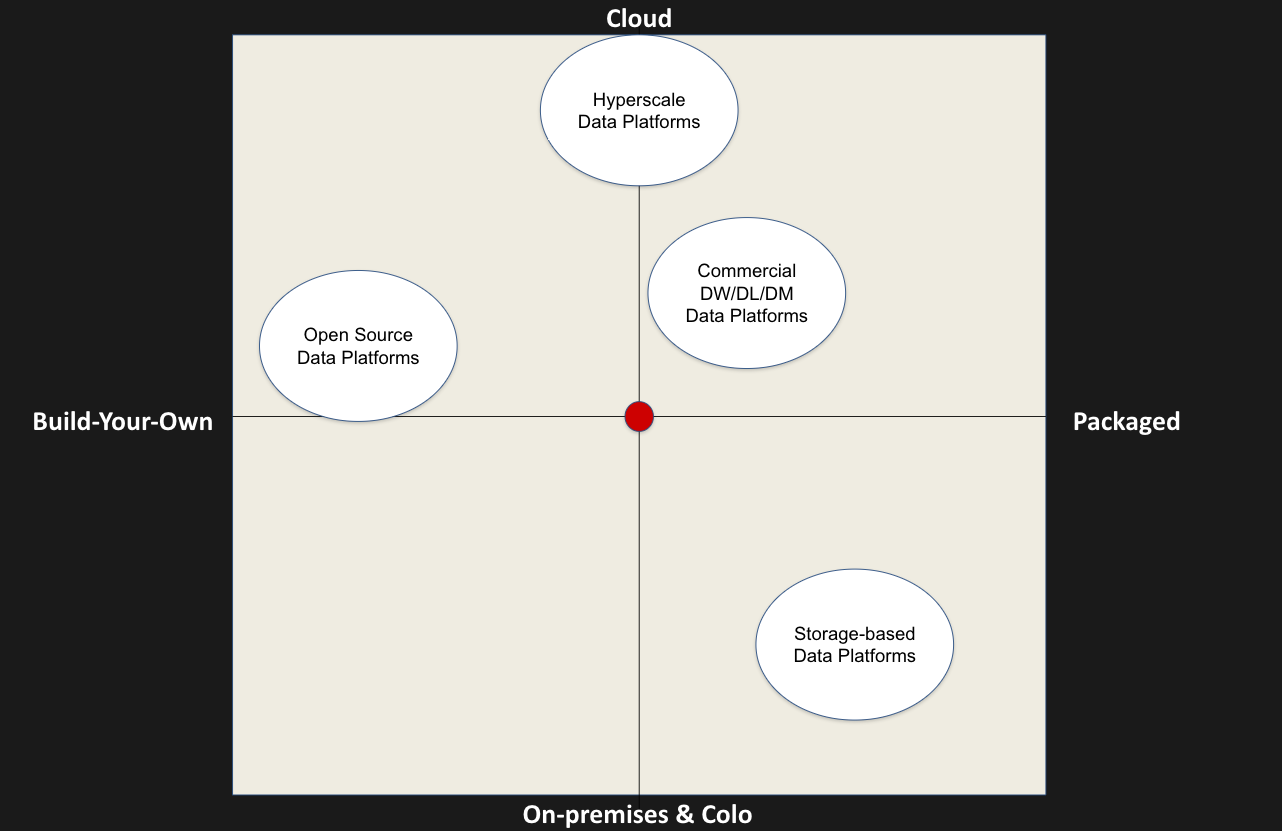
After completing our SWO analysis, we produced the quadrant diagram, presented in the analysis, to provide a simplified perspective on the integration flexibility of different data platforms. The diagram considers factors such as whether the platform is build-your-own or packaged, and the deployment options of cloud-native, on-premises or colocation. The analysis acknowledges that organizations often use multiple data platforms based on their specific use cases, and no single platform is likely to dominate an entire organization.
The hyperscaler clouds, while offering advantages in terms of infrastructure and scaling, score poorly in terms of hybrid capabilities due to their tight integration with their own services. Commercial data platforms, on the other hand, show some improvements in hybrid capabilities and offer more packaging options. They often integrate with other technologies and strike a balance between build-your-own and fully packaged solutions.
Storage data platforms are highly packaged and well-integrated from a storage perspective but may require further integration for data platform services, such as Spark or Kafka. However, these platforms are evolving and moving closer to the center, leveraging open-source technologies and investing in open-source communities to thrive. The convergence of open source and storage data platforms is an interesting trend to watch.
Considering the deployment options is crucial when evaluating data platforms, as most organizations have a mix of on-premises, colocation and hyperscaler environments. Costs can vary significantly depending on the components chosen, with tradeoffs between vendor consolidation and skill gaps. Choosing who bundles and runs the platform is another major decision, as it impacts skill requirements and costs. The choice between a single platform and a build-your-own platform also entails different cost considerations, such as software, hardware and personnel expenses.
Additionally, the choice of compute and storage options can vary and may involve skills gaps. Leveraging existing expertise in AWS, Azure, GCP or Oracle could be advantageous for running data platforms effectively. Overall, the analysis emphasizes that the selection and deployment of a data platform should not only consider its location but also how it integrates with existing infrastructure and aligns with organizational goals.
In conclusion, the Analyst Angle on the brewing data platform battle highlights the key factors that organizations should consider when evaluating and implementing data platforms. The evolving landscape and the interplay between various factors make it an exciting market to watch.
Feel free to reach out and stay connected through robs@siliconangle.com, DM @realstrech on Twitter and comment on our LinkedIn posts.
Also, check out this ETR Tutorial we created, which explains the spending methodology in more detail. Note: ETR is a separate company from Wikibon and SiliconANGLE. If you would like to cite or republish any of the company’s data, or inquire about its services, please contact ETR at legal@etr.ai.
Here’s the full Analyst Angle:
THANK YOU





